空间搜索-GeoHash
一. GeoHash 算法
1. Geohash 算法简介
Geohash 是一种地理编码,由 Gustavo Niemeyer 在2008年发明的,G.M.Morton在1966年做过类似的工作。。它是一种分级的数据结构,把空间划分为网格。Geohash 属于空间填充曲线中的 Z 阶曲线(Z-order curve)的实际应用。
何为 Z 阶曲线?
上图就是 Z 阶曲线。这个曲线比较简单,生成它也比较容易,只需要把每个 Z 首尾相连即可。
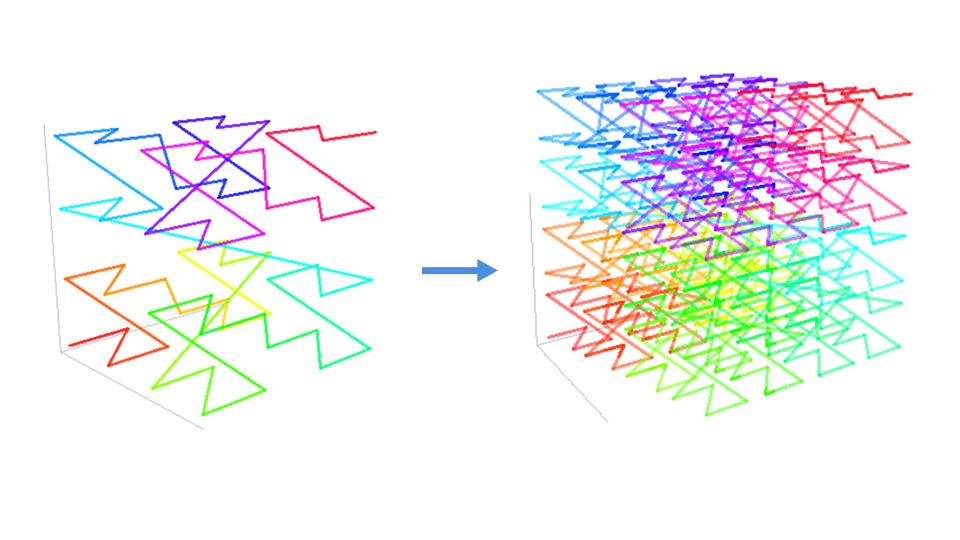
Z 阶曲线同样可以扩展到三维空间。只要 Z 形状足够小并且足够密,也能填满整个三维空间。
说到这里可能读者依旧一头雾水,不知道 Geohash 和 Z 曲线究竟有啥关系?其实 Geohash算法 的理论基础就是基于 Z 曲线的生成原理。继续说回 Geohash。
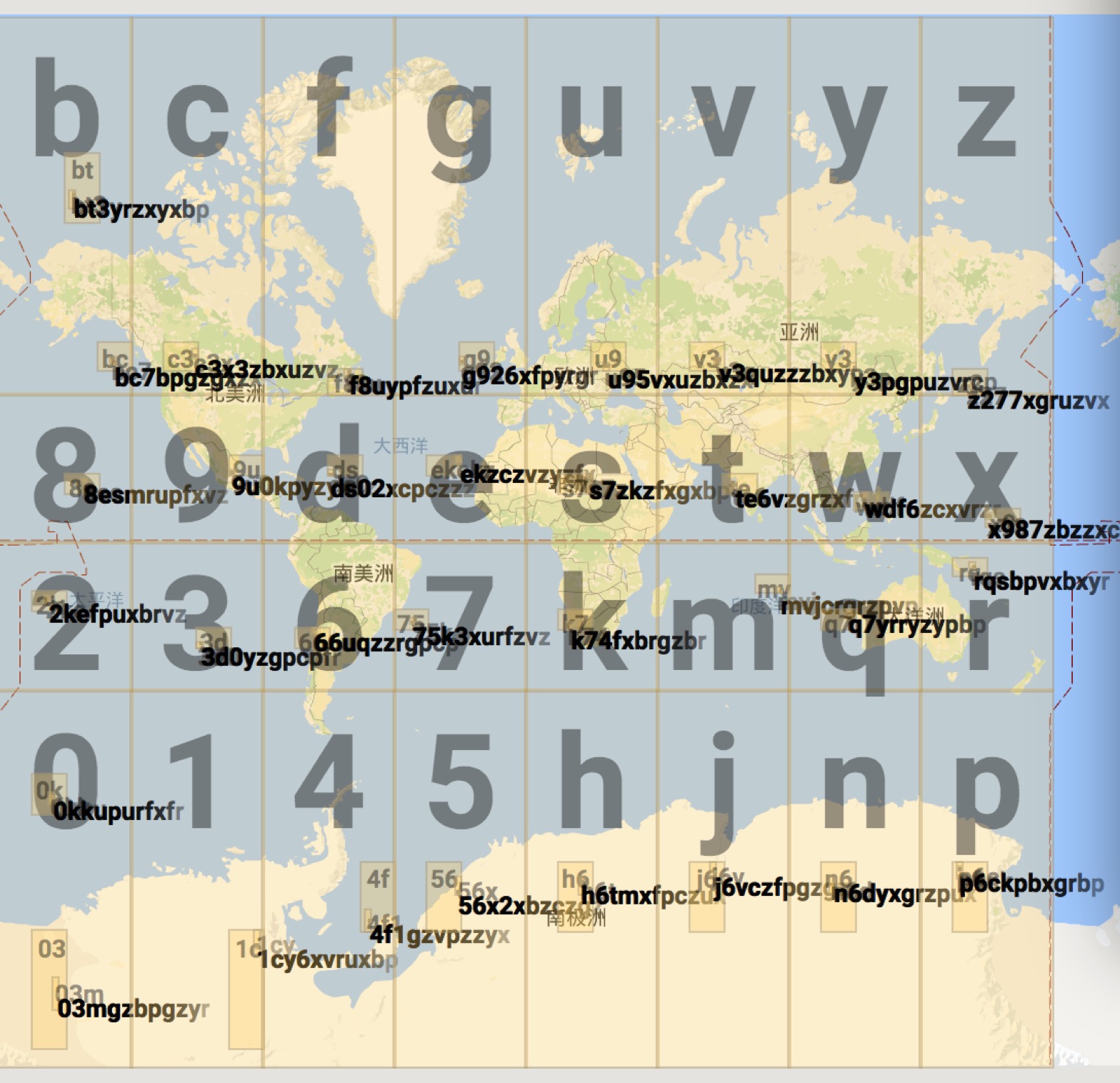
Geohash 能够提供任意精度的分段级别。一般分级从 1-12 级。
| 字符串长度 | cell 宽度 | cell 高度 | ||
|---|---|---|---|---|
| 1 | ≤ | 5,000km | × | 5,000km |
| 2 | ≤ | 1,250km | × | 625km |
| 3 | ≤ | 156km | × | 156km |
| 4 | ≤ | 39.1km | × | 19.5km |
| 5 | ≤ | 4.89km | × | 4.89km |
| 6 | ≤ | 1.22km | × | 0.61km |
| 7 | ≤ | 153m | × | 153m |
| 8 | ≤ | 38.2m | × | 19.1m |
| 9 | ≤ | 4.77m | × | 4.77m |
| 10 | ≤ | 1.19m | × | 0.596m |
| 11 | ≤ | 149mm | × | 149mm |
| 12 | ≤ | 37.2mm | × | 18.6mm |
还记得引语里面提到的问题么?这里我们就可以用 Geohash 来解决这个问题。
我们可以利用 Geohash 的字符串长短来决定要划分区域的大小。这个对应关系可以参考上面表格里面 cell 的宽和高。一旦选定 cell 的宽和高,那么 Geohash 字符串的长度就确定下来了。这样我们就把地图分成了一个个的矩形区域了。
地图上虽然把区域划分好了,但是还有一个问题没有解决,那就是如何快速的查找一个点附近邻近的点和区域呢?
Geohash 有一个和 Z 阶曲线相关的性质,那就是一个点附近的地方(但不绝对) hash 字符串总是有公共前缀,并且公共前缀的长度越长,这两个点距离越近。
由于这个特性,Geohash 就常常被用来作为唯一标识符。用在数据库里面可用 Geohash 来表示一个点。Geohash 这个公共前缀的特性就可以用来快速的进行邻近点的搜索。越接近的点通常和目标点的 Geohash 字符串公共前缀越长(但是这不一定,也有特殊情况,下面举例会说明)
Geohash 也有几种编码形式,常见的有2种,base 32 和 base 36。
| Decimal | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Base 32 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | b | c | d | e | f | g |
| Decimal | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Base 32 | h | j | k | m | n | p | q | r | s | t | u | v | w | x | y | z |
base 36 的版本对大小写敏感,用了36个字符,“23456789bBCdDFgGhHjJKlLMnNPqQrRtTVWX”。
| Decimal | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Base 36 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | b | B | C | d | D | F | g | G | h | H | j |
| Decimal | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Base 36 | J | K | I | L | M | n | N | P | q | Q | r | R | t | T | V | W | X |
2. Geohash 实际应用举例
接下来的举例以 base-32 为例。举个例子。
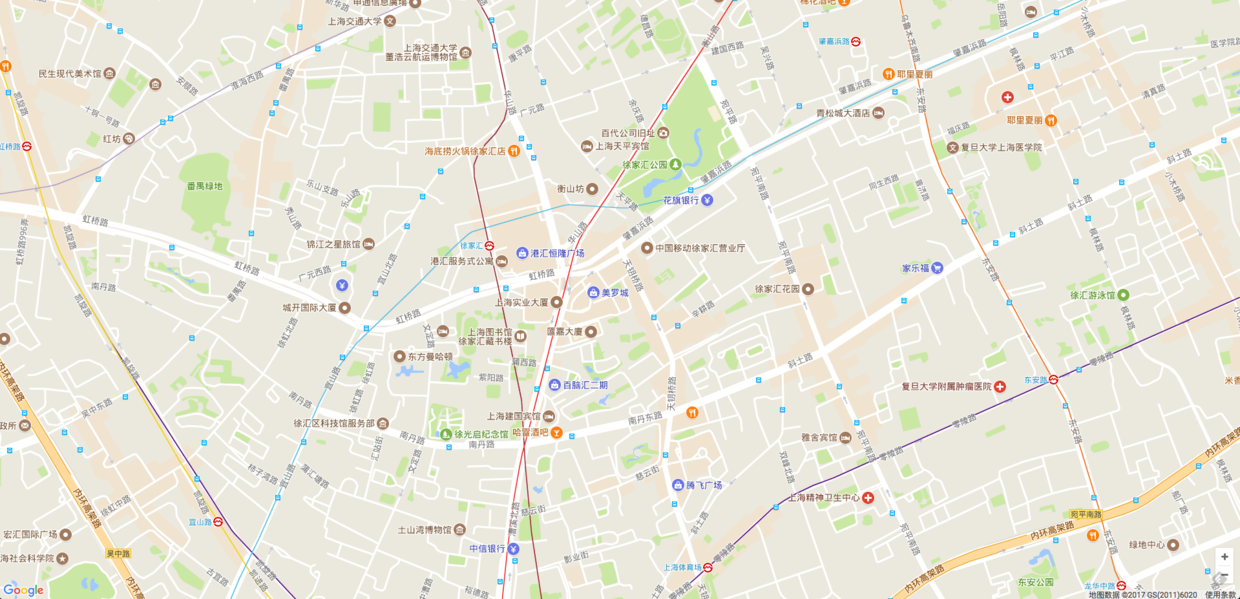
上图是一个地图,地图中间有一个美罗城,假设需要查询距离美罗城最近的餐馆,该如何查询?
第一步我们需要把地图网格化,利用 geohash。通过查表,我们选取字符串长度为6的矩形来网格化这张地图。
经过查询,美罗城的经纬度是[31.1932993, 121.43960190000007]。
先处理纬度。地球的纬度区间是[-90,90]。把这个区间分为2部分,即[-90,0),[0,90]。31.1932993位于(0,90]区间,即右区间,标记为1。然后继续把(0,90]区间二分,分为[0,45),[45,90],31.1932993位于[0,45)区间,即左区间,标记为0。一直划分下去。
| 左区间 | 中值 | 右区间 | 二进制结果 |
|---|---|---|---|
| -90 | 0 | 90 | 1 |
| 0 | 45 | 90 | 0 |
| 0 | 22.5 | 45 | 1 |
| 22.5 | 33.75 | 45 | 0 |
| 22.5 | 28.125 | 33.75 | 1 |
| 28.125 | 30.9375 | 33.75 | 1 |
| 30.9375 | 32.34375 | 33.75 | 0 |
| 30.9375 | 31.640625 | 32.34375 | 0 |
| 30.9375 | 31.2890625 | 31.640625 | 0 |
| 30.9375 | 31.1132812 | 31.2890625 | 1 |
| 31.1132812 | 31.2011718 | 31.2890625 | 0 |
| 31.1132812 | 31.1572265 | 31.2011718 | 1 |
| 31.1572265 | 31.1791992 | 31.2011718 | 1 |
| 31.1791992 | 31.1901855 | 31.2011718 | 1 |
| 31.1901855 | 31.1956786 | 31.2011718 | 0 |
再处理经度,一样的处理方式。地球经度区间是[-180,180]
| 左区间 | 中值 | 右区间 | 二进制结果 |
|---|---|---|---|
| -180 | 0 | 180 | 1 |
| 0 | 90 | 180 | 1 |
| 90 | 135 | 180 | 0 |
| 90 | 112.5 | 135 | 1 |
| 112.5 | 123.75 | 135 | 0 |
| 112.5 | 118.125 | 123.75 | 1 |
| 118.125 | 120.9375 | 123.75 | 1 |
| 120.9375 | 122.34375 | 123.75 | 0 |
| 120.9375 | 121.640625 | 122.34375 | 0 |
| 120.9375 | 121.289062 | 121.640625 | 1 |
| 121.289062 | 121.464844 | 121.640625 | 0 |
| 121.289062 | 121.376953 | 121.464844 | 1 |
| 121.376953 | 121.420898 | 121.464844 | 1 |
| 121.420898 | 121.442871 | 121.464844 | 0 |
| 121.420898 | 121.431885 | 121.442871 | 1 |
纬度产生的二进制是101011000101110,经度产生的二进制是110101100101101,按照“偶数位放经度,奇数位放纬度”的规则,重新组合经度和纬度的二进制串,生成新的:111001100111100000110011110110,最后一步就是把这个最终的字符串转换成字符,对应需要查找 base-32 的表。11100 11001 11100 00011 00111 10110转换成10进制是 28 25 28 3 7 22,查表编码得到最终结果: wtw37q。
我们还可以把这个网格周围8个各自都计算出来。
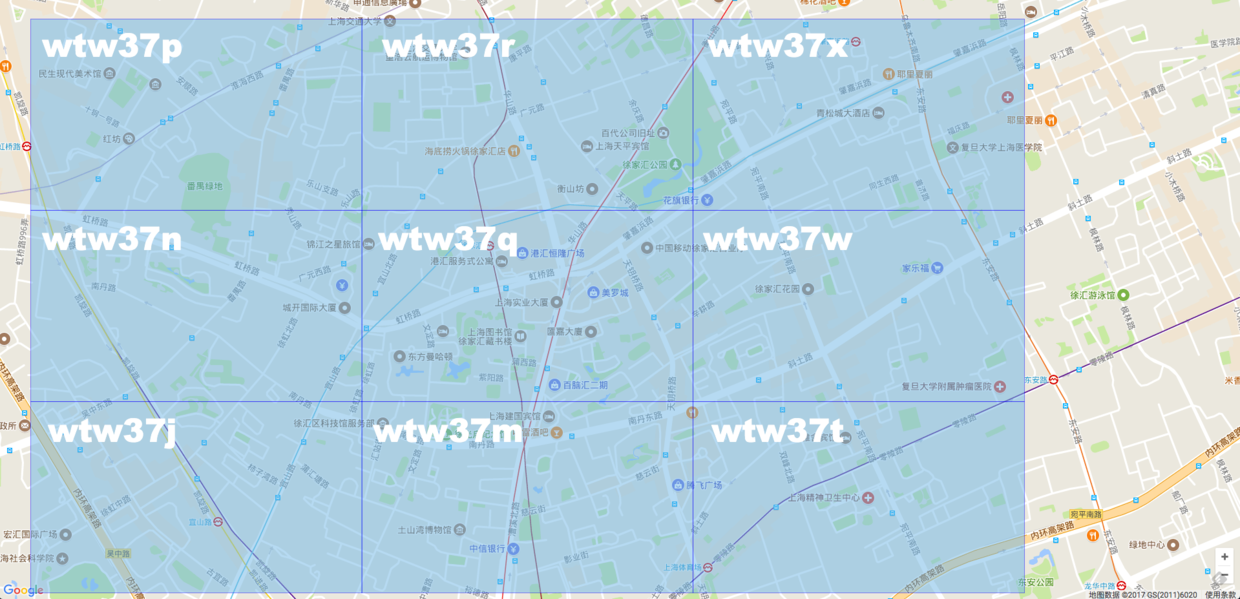
从地图上可以看出,这邻近的9个格子,前缀都完全一致。都是wtw37。
如果我们把字符串再增加一位,会有什么样的结果呢?Geohash 增加到7位。
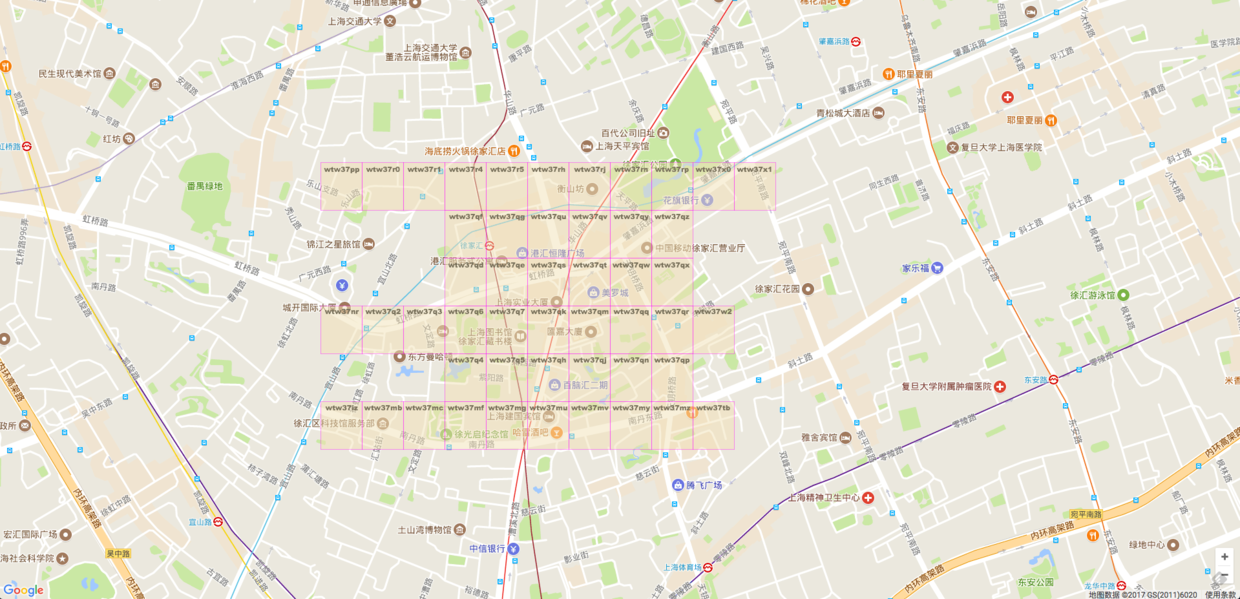
当Geohash 增加到7位的时候,网格更小了,美罗城的 Geohash 变成了 wtw37qt。
看到这里,读者应该已经清楚了 Geohash 的算法原理了。咱们把6位和7位都组合到一张图上面来看。
可以看到中间大格子的 Geohash 的值是 wtw37q,那么它里面的所有小格子前缀都是 wtw37q。可以想象,当 Geohash 字符串长度为5的时候,Geohash 肯定就为 wtw37 了。
接下来解释之前说的 Geohash 和 Z 阶曲线的关系。回顾最后一步合并经纬度字符串的规则,“偶数位放经度,奇数位放纬度”。读者一定有点好奇,这个规则哪里来的?凭空瞎想的?其实并不是,这个规则就是 Z 阶曲线。看下图:
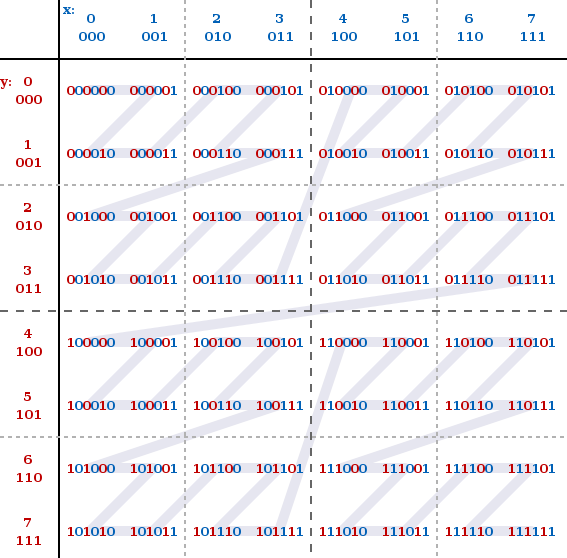
x 轴就是纬度,y轴就是经度。经度放偶数位,纬度放奇数位就是这样而来的。
最后有一个精度的问题。
| Geohash 长度 | Lat位数 | Lng位数 | Lat误差 | 误差 | km误差 |
|---|---|---|---|---|---|
| 1 | 2 | 3 | ±23 | ±23 | ±2500 |
| 2 | 5 | 5 | ±2.8 | ±5.6 | ±630 |
| 3 | 7 | 8 | ±0.70 | ±0.70 | ±78 |
| 4 | 10 | 10 | ±0.087 | ±0.18 | ±20 |
| 5 | 12 | 13 | ±0.022 | ±0.022 | ±2.4 |
| 6 | 15 | 15 | ±0.0027 | ±0.0055 | ±0.61 |
| 7 | 17 | 18 | ±0.00068 | ±0.00068 | ±0.076 |
| 8 | 20 | 20 | ±0.000086 | ±0.000172 | ±0.019 |
| 9 | 22 | 23 | ±0.000021 | ±0.000021 | ±0.00478 |
| 10 | 25 | 25 | ±0.00000268 | ±0.00000536 | ±0.0005971 |
| 11 | 27 | 28 | ±0.00000067 | ±0.00000067 | ±0.0001492 |
| 12 | 30 | 30 | ±0.00000008 | ±0.00000017 | ±0.0000186 |
4. Geohash 的优缺点
Geohash 的优点很明显,它利用 Z 阶曲线进行编码。而 Z 阶曲线可以将二维或者多维空间里的所有点都转换成一维曲线。在数学上成为分形维。并且 Z 阶曲线还具有局部保序性。
Z 阶曲线通过交织点的坐标值的二进制表示来简单地计算多维度中的点的z值。一旦将数据被加到该排序中,任何一维数据结构,例如二叉搜索树,B树,跳跃表或(具有低有效位被截断)哈希表都可以用来处理数据。通过 Z 阶曲线所得到的顺序可以等同地被描述为从四叉树的深度优先遍历得到的顺序。
这也是 Geohash 的另外一个优点,搜索查找邻近点比较快。
Geohash 的缺点之一也来自 Z 阶曲线。
Z 阶曲线有一个比较严重的问题,虽然有局部保序性,但是它也有突变性。在每个 Z 字母的拐角,都有可能出现顺序的突变。
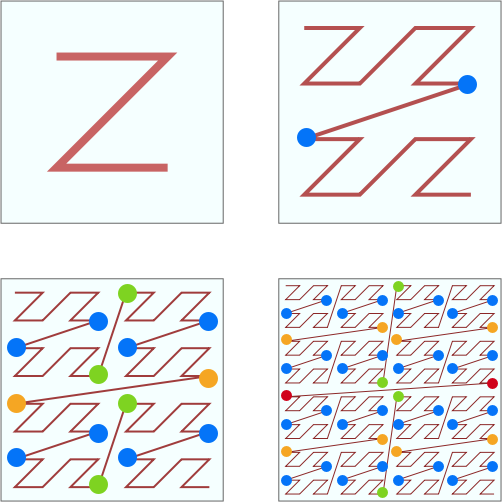
看上图中标注出来的蓝色的点点。每两个点虽然是相邻的,但是距离相隔很远。看右下角的图,两个数值邻近红色的点两者距离几乎达到了整个正方形的边长。两个数值邻近绿色的点也达到了正方形的一半的长度。
Geohash 的另外一个缺点是,如果选择不好合适的网格大小,判断邻近点可能会比较麻烦。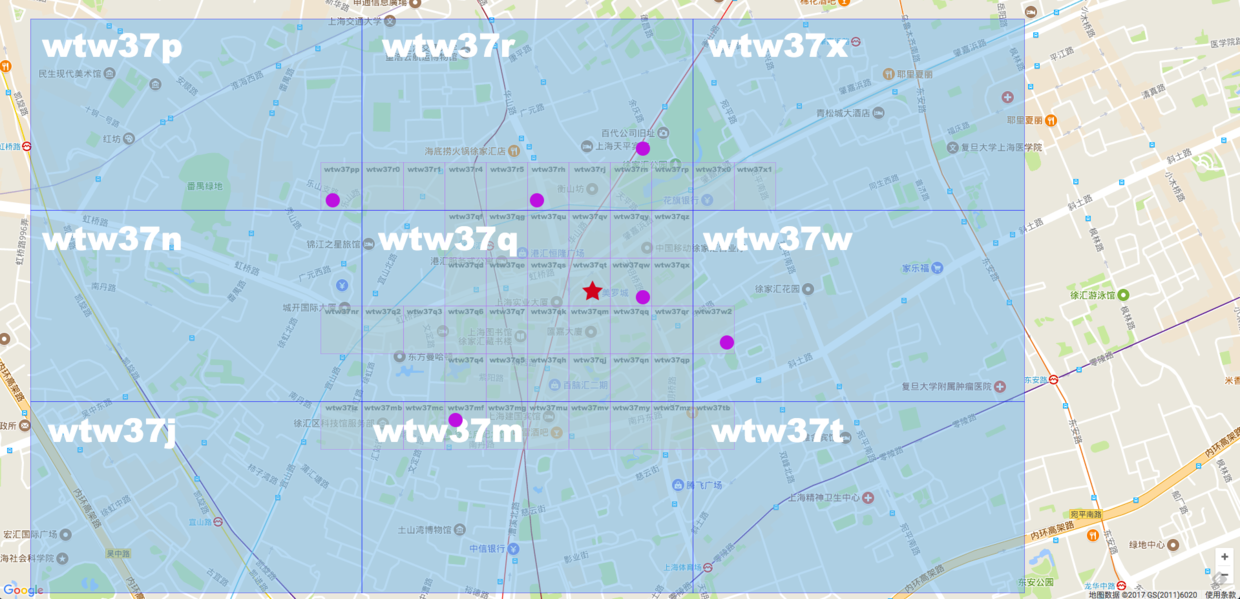
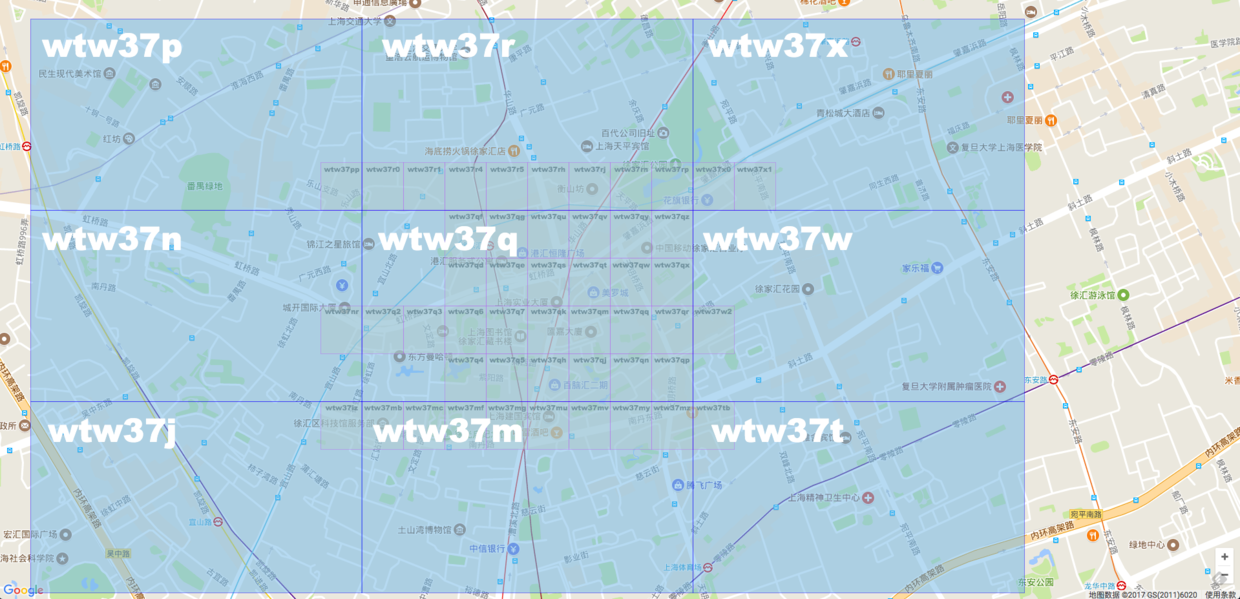
看上图,如果选择 Geohash 字符串为6的话,就是蓝色的大格子。红星是美罗城,紫色的圆点是搜索出来的目标点。如果用 Geohash 算法查询的话,距离比较近的可能是 wtw37p,wtw37r,wtw37w,wtw37m。但是其实距离最近的点就在 wtw37q。如果选择这么大的网格,就需要再查找周围的8个格子。
如果选择 Geohash 字符串为7的话,那变成黄色的小格子。这样距离红星星最近的点就只有一个了。就是 wtw37qw。
如果网格大小,精度选择的不好,那么查询最近点还需要再次查询周围8个点。
参考文档:
https://en.wikipedia.org/wiki/Geohash