缘起
公司业务由于广告以及导流的影响,对搜索服务的稳定以及性能提出了更苛刻的要求,为了应对可能的流量突增,特进行了大规模,全方位的性能测试。摸清线上服务的能力,以及定位瓶颈所在。
搜索服务采用了Master-Slave的Redis服务来缓存用户的搜索结果,过期时间在5~10分钟,通过缓存来提升响应时间和并发。key是用户的请求实体json字符串,value自然是搜索结果json串,并没有使用set,hash等类型。
Redis瓶颈
经过一轮的性能测试,最终的瓶颈点落在了Redis上,如下图Grafana监控所示:
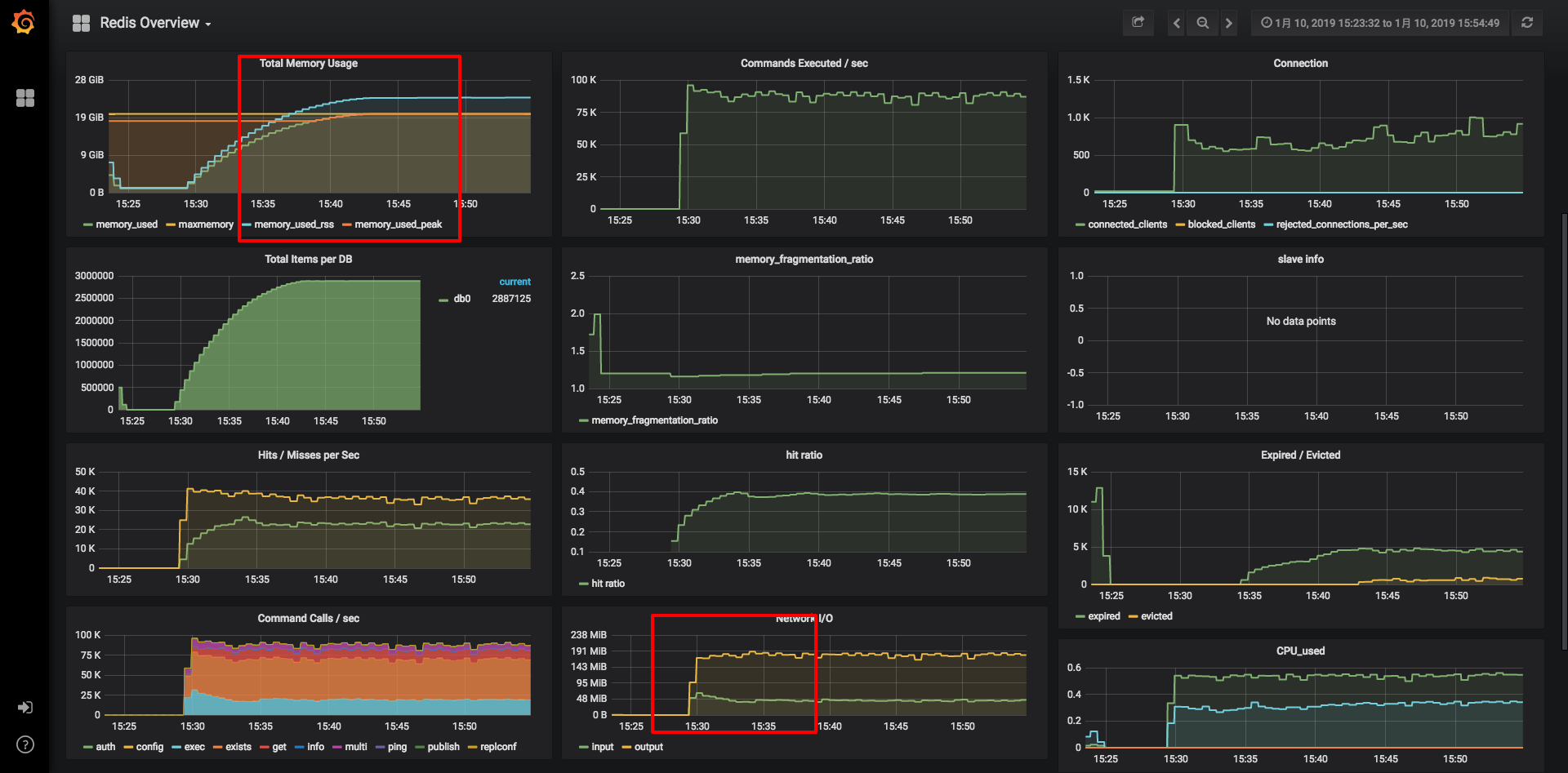
在请求和并发上去之后,redis item迅速增长到300W左右,每秒command数达到近10W。由于redis存储做了限制20G,图中可以看到内存已经满了,item肯定会被频繁置换出去,总数提升不上去。从network上看,output已经达到了近200MB/s,远超运维的限制的100MB/s(千兆网卡极限约100MB,万兆约1000MB)。
核心瓶颈点:
Redis bigkey解决
所谓的BigKey,大概有以下的情况:
- String本身比较大
- set,hash内个数比较大
在我们的这个场景下,主要是json串太大。这涉及到key, value的如果减小的问题。
先来看key如何减小:
我们是使用fastjson来对Request对象做序列化的,key就是这个json串。
1
2
| Request request = (Request) obj;
String json = JSON.toJSONString(request);
|
直接想到的就是对key做编码,减小长度。使用了commons-codec里的md5加密摘要,作为key。
1
| DigestUtils.md5Hex(json)
|
这样就保证了key的长度缩小,并且长度一致。需要注意的是MD5有一定的冲突率,在本场景下可以基本忽略。
接下来,看value如何缩小:
value的序列化,我们使用的是jackson2来做的,反序列化的时候直接就是对象,方便配合Spring Cache使用。核心代码如下:
1
2
3
4
5
6
7
8
| private RedisSerializer getValueSerializer() {
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
return jackson2JsonRedisSerializer;
}
|
redis里存储的就是jackson2转化后的字符串,其中包含了class等相关信息。
当然,从业务上减小每次查询的搜索结果条数是一个办法,比如每次最多只能查询10条。但是,如果10条的数据仍旧比较大,我们想到的直接方法就是压缩。
直接使用JDK自带的GZIP压缩来实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| public class GzipSerializer implements RedisSerializer<Object> {
public static final int BUFFER_SIZE = 4096;
private RedisSerializer<Object> innerSerializer;
public GzipSerializer(RedisSerializer<Object> innerSerializer) {
this.innerSerializer = innerSerializer;
}
@Override
public byte[] serialize(Object graph) throws SerializationException {
if (graph == null) {
return new byte[0];
}
ByteArrayOutputStream bos = null;
GZIPOutputStream gzip = null;
try {
byte[] bytes = innerSerializer.serialize(graph);
bos = new ByteArrayOutputStream();
gzip = new GZIPOutputStream(bos);
gzip.write(bytes);
gzip.finish();
byte[] result = bos.toByteArray();
return result;
} catch (Exception e) {
throw new SerializationException("Gzip Serialization Error", e);
} finally {
IOUtils.closeQuietly(bos);
IOUtils.closeQuietly(gzip);
}
}
@Override
public Object deserialize(byte[] bytes) throws SerializationException {
if (bytes == null || bytes.length == 0) {
return null;
}
ByteArrayOutputStream bos = null;
ByteArrayInputStream bis = null;
GZIPInputStream gzip = null;
try {
bos = new ByteArrayOutputStream();
bis = new ByteArrayInputStream(bytes);
gzip = new GZIPInputStream(bis);
byte[] buff = new byte[BUFFER_SIZE];
int n;
while ((n = gzip.read(buff, 0, BUFFER_SIZE)) > 0) {
bos.write(buff, 0, n);
}
Object result = innerSerializer.deserialize(bos.toByteArray());
return result;
} catch (Exception e) {
throw new SerializationException("Gzip deserizelie error", e);
} finally {
IOUtils.closeQuietly(bos);
IOUtils.closeQuietly(bis);
IOUtils.closeQuietly(gzip);
}
}
}
|
通过这个GzipSerializer实现了压缩功能,并且最大可能的减少了对原始代码的改动。
1
2
3
4
5
6
7
8
| @Bean
public RedisTemplate<String, String> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
StringRedisTemplate template = new StringRedisTemplate(redisConnectionFactory);
template.setValueSerializer(new GzipSerializer(getValueSerializer()));
template.afterPropertiesSet();
return template;
}
|
更改之后,进行新一轮的性能压测。grafana监控效果如下:
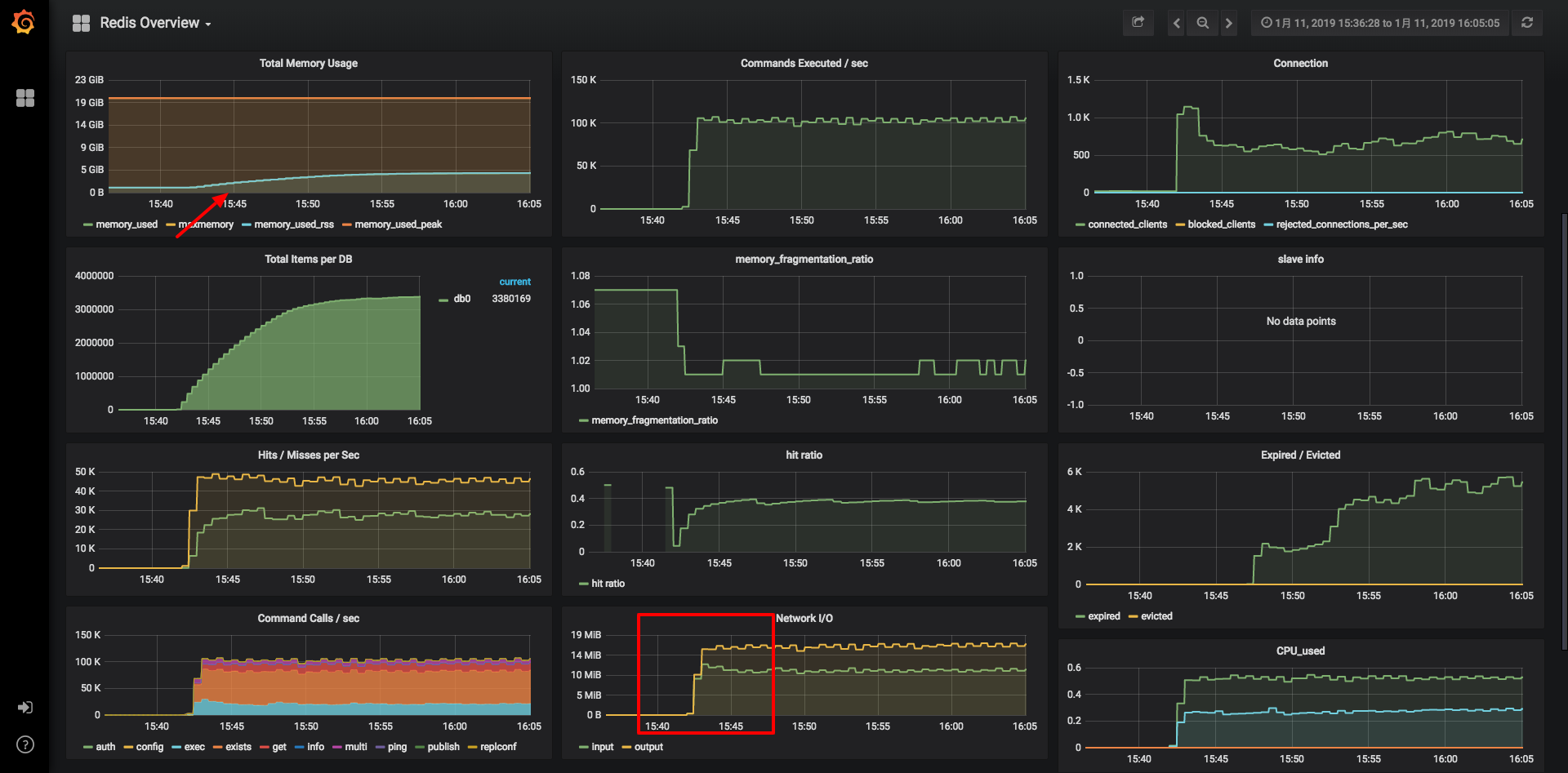
可以看出,同样的压力情况下。内存占用不到5G,网络IO也在14M/S上下,效果显著。顺利的解决了Redis的瓶颈所在。
至此压力测试到一个阶段,下面来看一下,功能在生产环境的使用情况如何。
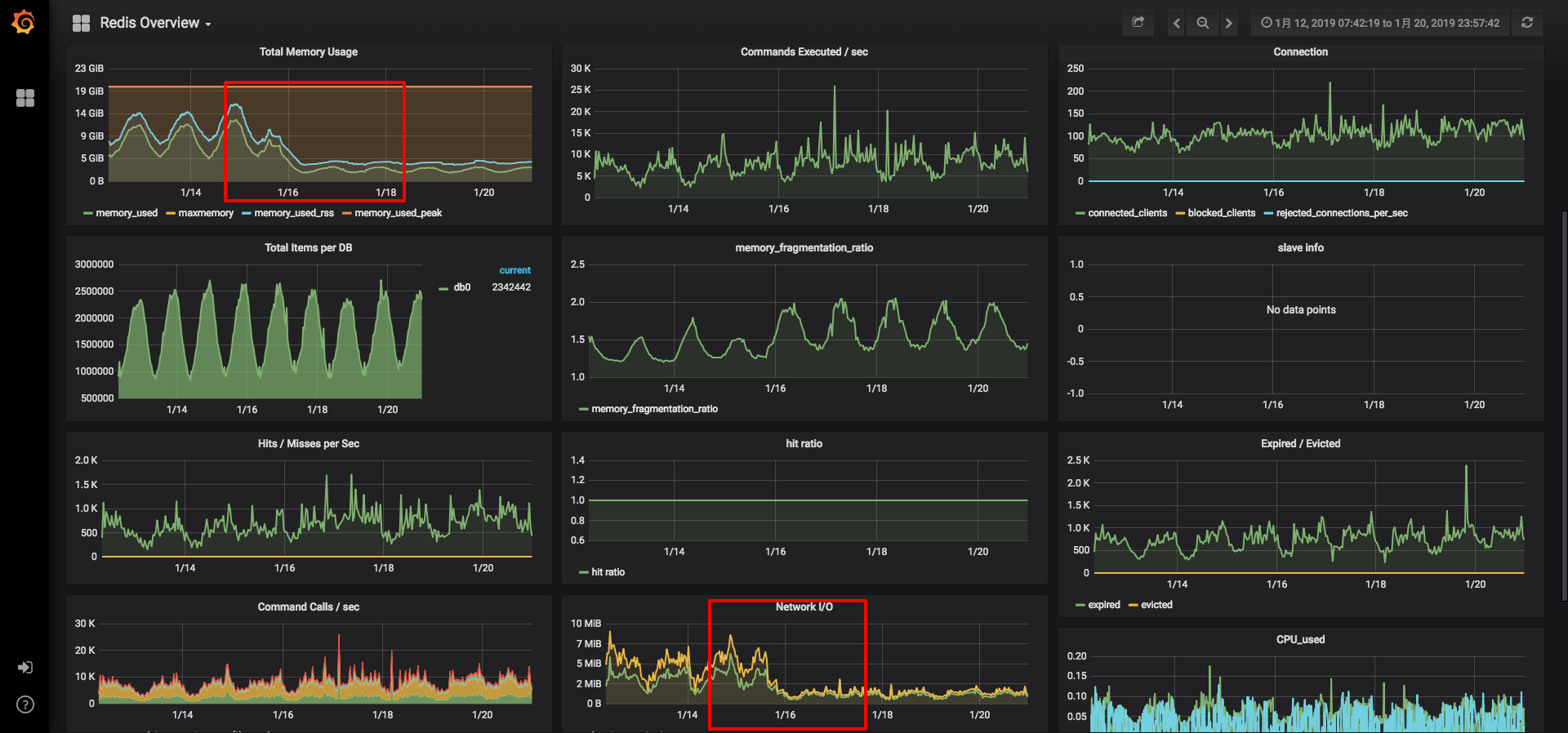
从上面看出,在1.16上线后,在整体流量基本不变的情况下,内存以及网络IO大幅度下降,经受住了生产环境的考验。
有没有更好的方案
以上,为了解决Redis瓶颈,通过MD5摘要以及压缩快速而小改动的解决了问题,如果从长远来看,如何才能做到更好呢?
压缩方式-性能&压缩比兼顾
GZIP能取得不错的压缩比,但是对CPU要求较高,相当于把redis的存储瓶颈转移到了Java程序的解压缩上。是否有一个性能和压缩比兼得的压缩方案呢?
从参考1中,可以一探究竟。
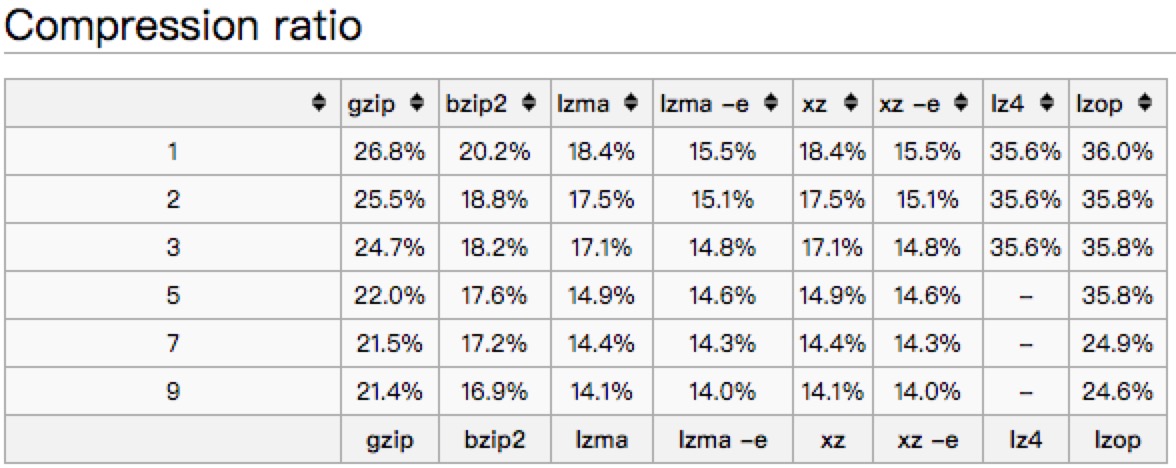
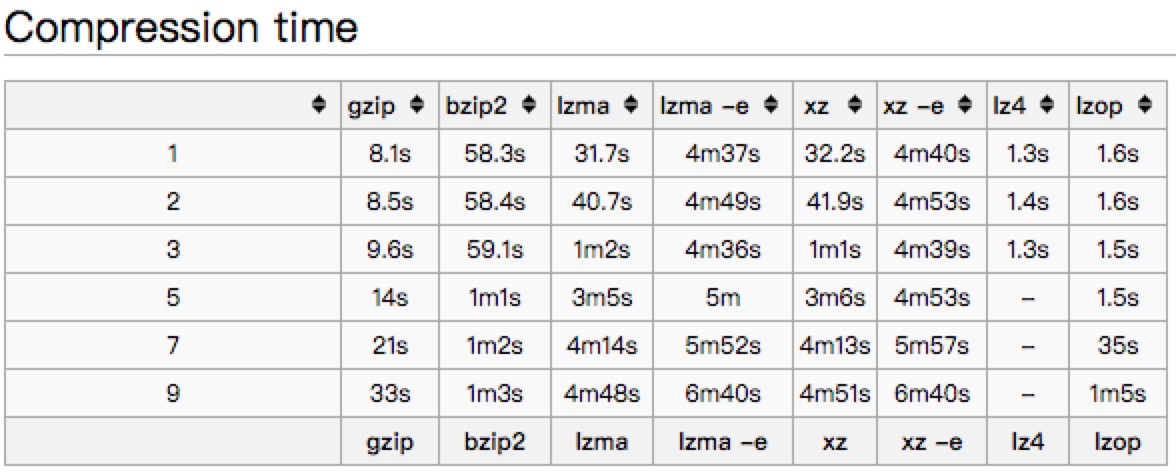
文中以一个445M的文件对常见的压缩方式进行了比较。
压缩后的大小:
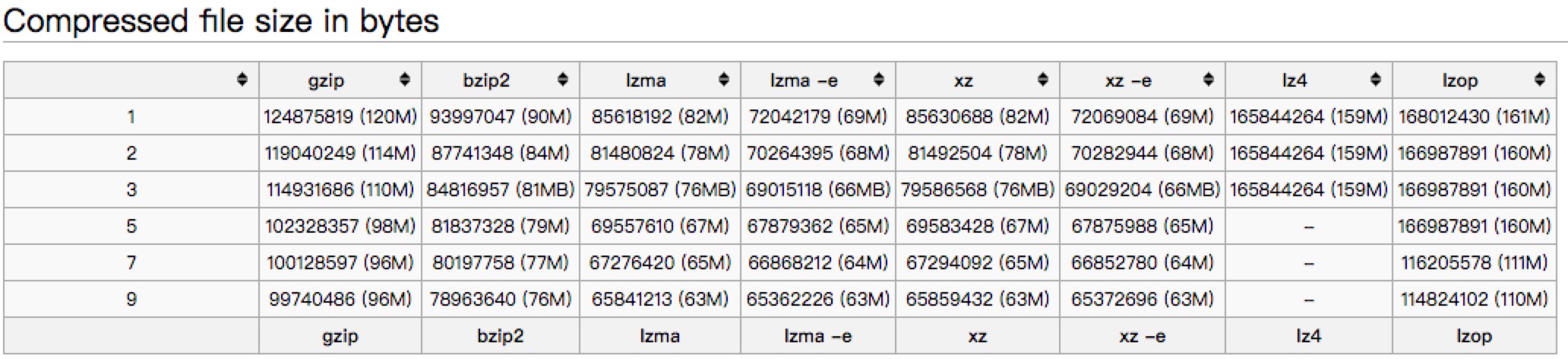
压缩比:
压缩耗时:
解压缩耗时:
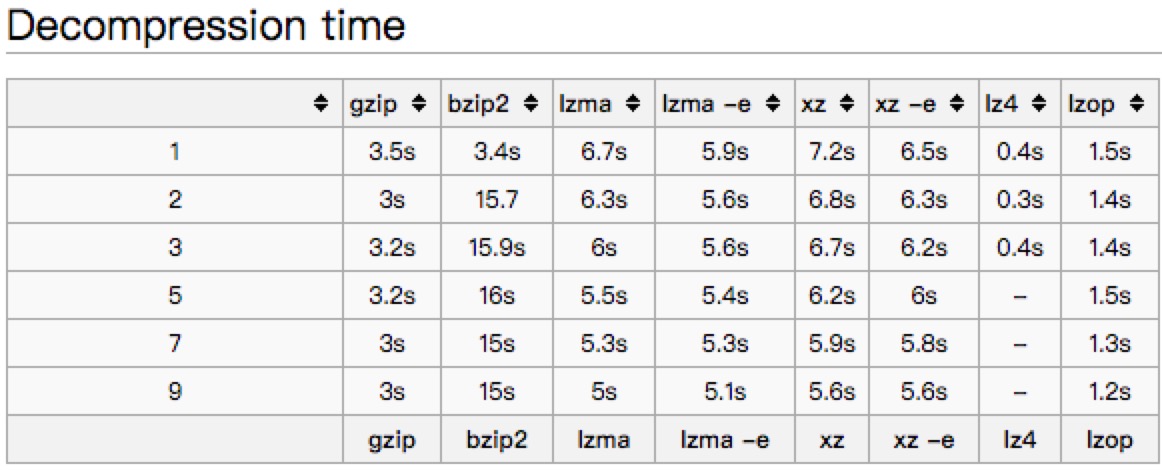
从以上的benchmark对比来看,不同压缩方式优劣不一样,大家可以根据实际情况来选择。
个人推荐来看,也许LZ4是一个不错的选择,压缩比高一些,但是解压缩速度都比gzip要高。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
| import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import org.apache.commons.io.IOUtils;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.SerializationException;
import net.jpountz.lz4.LZ4BlockInputStream;
import net.jpountz.lz4.LZ4BlockOutputStream;
import net.jpountz.lz4.LZ4Compressor;
import net.jpountz.lz4.LZ4Factory;
import net.jpountz.lz4.LZ4FastDecompressor;
public class LZ4Serializer implements RedisSerializer<Object> {
private static final int BUFFER_SIZE = 4096;
private RedisSerializer<Object> innerSerializer;
private LZ4FastDecompressor decompresser;
private LZ4Compressor compressor;
public LZ4Serializer(RedisSerializer<Object> innerSerializer) {
this.innerSerializer = innerSerializer;
LZ4Factory factory = LZ4Factory.fastestInstance();
this.compressor = factory.fastCompressor();
this.decompresser = factory.fastDecompressor();
}
@Override
public byte[] serialize(Object graph) throws SerializationException {
if (graph == null) {
return new byte[0];
}
ByteArrayOutputStream byteOutput = null;
LZ4BlockOutputStream compressedOutput = null;
try {
byte[] bytes = innerSerializer.serialize(graph);
byteOutput = new ByteArrayOutputStream();
compressedOutput = new LZ4BlockOutputStream(byteOutput, BUFFER_SIZE, compressor);
compressedOutput.write(bytes);
compressedOutput.finish();
byte[] compressBytes = byteOutput.toByteArray();
return compressBytes;
} catch (Exception e) {
throw new SerializationException("LZ4 Serialization Error", e);
} finally {
IOUtils.closeQuietly(compressedOutput);
IOUtils.closeQuietly(byteOutput);
}
}
@Override
public Object deserialize(byte[] bytes) throws SerializationException {
if (bytes == null || bytes.length == 0) {
return null;
}
ByteArrayOutputStream baos = null;
LZ4BlockInputStream lzis = null;
try {
baos = new ByteArrayOutputStream(BUFFER_SIZE);
lzis = new LZ4BlockInputStream(new ByteArrayInputStream(bytes), decompresser);
int count;
byte[] buffer = new byte[BUFFER_SIZE];
while ((count = lzis.read(buffer)) != -1) {
baos.write(buffer, 0, count);
}
Object result = innerSerializer.deserialize(baos.toByteArray());
return result;
} catch (Exception e) {
throw new SerializationException("LZ4 deserizelie error", e);
} finally {
IOUtils.closeQuietly(lzis);
IOUtils.closeQuietly(baos);
}
}
}
|
序列化方案
前面提到,我们的序列化方案是基于json的,那有没有更好的序列化方案,能够有更好的性能,更低的内存占用。
序列化方案无论是在redis,还是在各种RPC解决方案里都是大家热烈讨论的话题。那我们来看一下主要序列化方案的一些对比。
在参考2和3里都有提及。
各种序列化方案字节大小对比(越小越好):
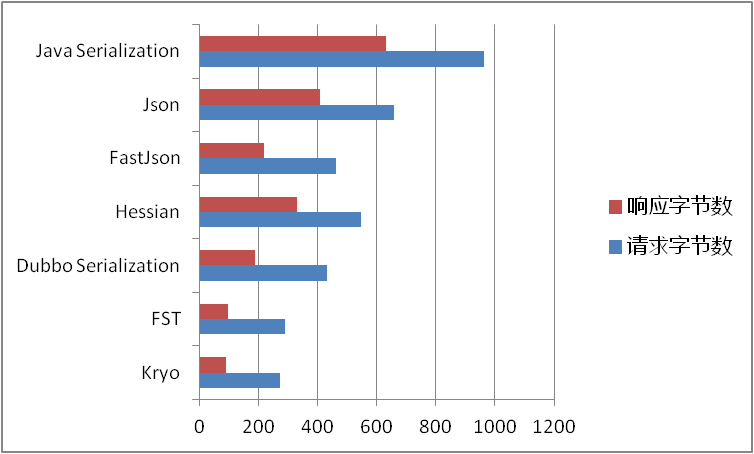
耗时对比(越小越好):
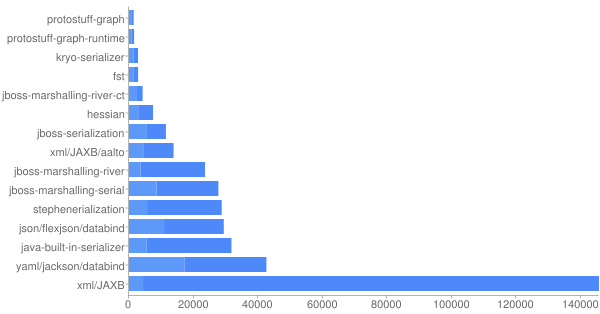
综合以上文章所述,再加上易用性的使用角度,个人推荐倾向于:
当然关于Java对象的序列化,不同方案也有一些差异,比如是否实现Serializable接口,是否支持嵌套内部类在选择的时候,也都是需要注意的。
下面给一个kryo的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.SerializationException;
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.io.Input;
import com.esotericsoftware.kryo.io.Output;
public class KryoSerializer<T> implements RedisSerializer<T> {
private static final int BUFFER_SIZE = 2048;
private static final byte[] EMPTY_BYTE_ARRAY = new byte[0];
private static final ThreadLocal<Kryo> KRYOS = ThreadLocal.withInitial(Kryo::new);
@Override
public byte[] serialize(T t) throws SerializationException {
if (null == t) {
return EMPTY_BYTE_ARRAY;
}
Output output = new Output(BUFFER_SIZE, -1);
Kryo kryo = KRYOS.get();
kryo.writeClassAndObject(output, t);
output.flush();
return output.toBytes();
}
@Override
public T deserialize(byte[] bytes) throws SerializationException {
if (null == bytes || bytes.length <= 0) {
return null;
}
Input input = new Input(bytes);
Kryo kryo = KRYOS.get();
T t = (T) kryo.readClassAndObject(input);
input.close();
return t;
}
}
|
使用Redis Cluster
前面提到的,无论是压缩还是序列化都是基于Redis无法扩容,以及单机网络IO限制的。如果为了支持更大的并发和更快的响应,我们需要使用Redis Cluster,当然也可以从客户角度进行拆分,使用多个Redis实例,这里不予表述。
Redis Cluster在3.0之后推出,用于解决Redis的分布式需求。自动的在不同节点之间均衡数据,充分利用多机的优势。
参考:
1.Quick Benchmark: Gzip vs Bzip2 vs LZMA vs XZ vs LZ4 vs LZO
2.Jvm-serializers
3.在Dubbo中使用高效的Java序列化(Kryo和FST)
4.Redis Cluster Specification