ElasticSearch-Nested嵌套类型解密

Lucene Field本身并不支持嵌套类型,最多也就支持多值类型。ElasticSearch进行了扩展,使得Field可以是object对象类型或者nested嵌套类型。
object类型,本质上是把字段路径打平,最终在索引里还是一个正常的Field字段,object类型转化后,并不会保留对象内的属性对应关系,这在查询中可能需要特别注意。然后nested嵌套类型却实现的对应关系。
使用上的区别,可以参考官方Nested Data Type。
本文,我们主要关注的是elasticsearch内部是如何实现的?
ElasticSearch的官方说法
Because nested documents are indexed as separate documents, they can only be accessed within the scope of the nested query, the nested/reverse_nestedaggregations, or nested inner hits.
For instance, if a string field within a nested document has index_options set to offsets to allow use of the postings during the highlighting, these offsets will not be available during the main highlighting phase. Instead, highlighting needs to be performed via nested inner hits.
Indexing a document with 100 nested fields actually indexes 101 documents as each nested document is indexed as a separate document. To safeguard against ill-defined mappings the number of nested fields that can be defined per index has been limited to 50. See Settings to prevent mappings explosionedit.
从这里的介绍,我们所知有限。能得到的结论如下:
- nested类型在索引里是作为Document单独存储的。nested类型可能是1个包含100数据的数组,那就是100个Document。每多1个nested类型,就多增加对应length的Document.
- 普通的query对nested字段查询无效,必须使用nested Query
- highlight高亮也需要使用专门的Query
- 对于nested类型的field个数是有限制的, 长度也是有限制的。
Nested类型怎么分开存储的
org.elasticsearch.index.mapper.DocumentParser类是专门用于解析要索引的Document的。
其中有这样一个方法来解析对象类型。
1 | static void parseObjectOrNested(ParseContext context, ObjectMapper mapper) throws IOException { |
下面来看是怎么处理的。
1 | private static ParseContext nestedContext(ParseContext context, ObjectMapper mapper) { |
总之,经过DocumentParser的处理,Nested Document多了这样的2个字段
- _id,值为父Document的id,用来关联
- _type,值为”__”开头的,标识特定nested 类型。
Nested类型普通Query如何隐藏
从上面存储知道,nested document是和普通Document一起存在索引中的,但对外是隐藏的,甚至是MatchAllQuery。
在org.elasticsearch.common.lucene.search.Queries类中:
1 | /** |
下面来看一下_primary_term是如何放进去的。这里涉及到org.elasticsearch.index.mapper.SeqNoFieldMapper这个类。他主要是用来为Document添加_seq_no元字段的,附带着把_primary_term给加了进去。
1 |
|
1 | public static SequenceIDFields emptySeqID() { |
下面,我们来看下,都什么地方使用到了Queries.newNonNestedFilter.这里我在IDEA里做了一个截图。
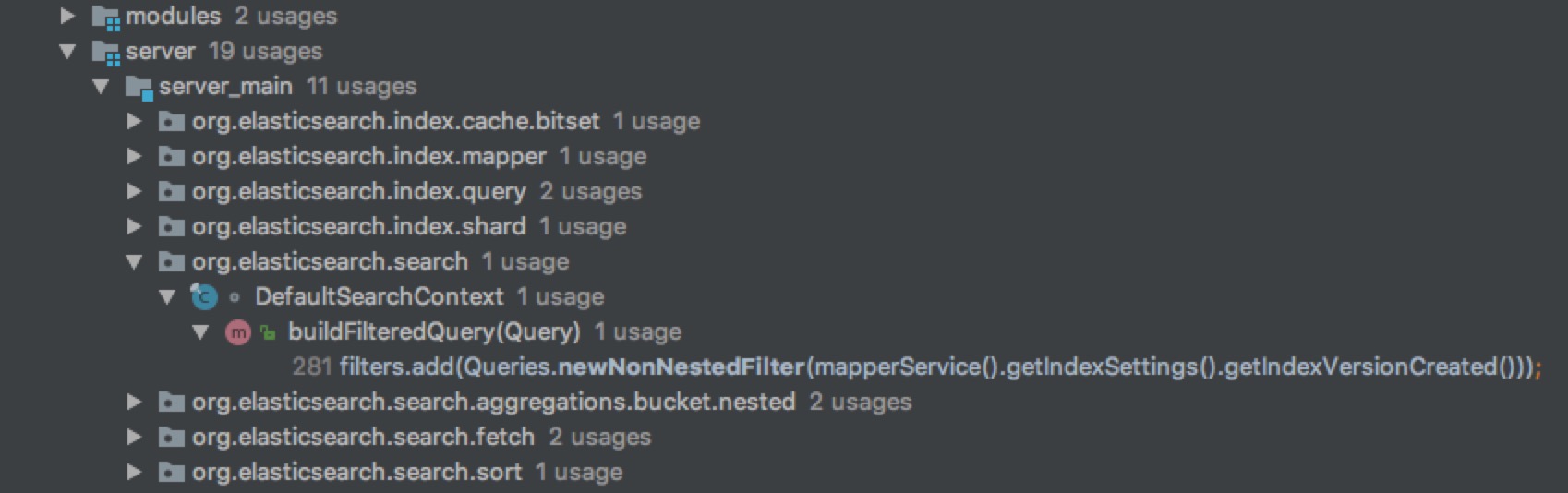
从上可以看出,基本的正常查询都默认加了这个filter的,只有是nestedQuery才做特别的处理。
总结下如何隐藏的:
| ElasticSearch版本 | 隐藏实现方式 |
|---|---|
| 小于6.1.0 | 过滤掉_type以“__”为前缀的nested document |
| 大于等于6.1.0 | 只获取有__primary_term Field的父Document |
综述
无论是ElasticSearch,还是Solr, 其底层都是通过Lucene来做索引的。Lucene本身并不支持这种嵌套类型。ElasticSearch通过一个比较hack的方式支持了这样的功能,用起来更加的顺手,功能更强大。
同时,我们通过上面的分析,Nested也是有缺点的。
- nested无形中增加了索引量,如果不了解具体实现,将无法很好的进行文档划分和预估。ES限制了Field个数和nested对象的size,避免无限制的扩大
- nested Query 整体性能慢,但比parent/child Query稍快。应从业务上尽可能的避免使用NestedQuery, 对于性能要求高的场景,应该直接禁止使用。