Redis数据模型详解
Redis对象
在Redis的世界里,存储的所有值都是这个RedisObject对象。
源码定义如下:
1 | typedef struct redisObject { |
其中type可以取值枚举如下:
| TYPE枚举 | VALUE值 | 代表 |
|---|---|---|
| OBJ_STRING | 0 | STRING |
| OBJ_LIST | 1 | LIST |
| OBJ_SET | 2 | SET |
| OBJ_ZSET | 3 | ZSET |
| OBJ_HASH | 4 | HASH |
| OBJ_MODULE | 5 | — |
| OBJ_STREAM | 6 | — |
不同类型Type,它的底层实现/编码方式也是不一样的。枚举类型如下:
| encoding枚举 | VALUE值 | str描述 |
|---|---|---|
| OBJ_ENCODING_RAW | 0 | raw |
| OBJ_ENCODING_INT | 1 | int |
| OBJ_ENCODING_HT | 2 | hashtable |
| OBJ_ENCODING_ZIPMAP | 3 | 不再使用, 转为ZIPLIST |
| OBJ_ENCODING_LINKEDLIST | 4 | 不再使用,转为QUICKLIST |
| OBJ_ENCODING_ZIPLIST | 5 | ziplist |
| OBJ_ENCODING_INTSET | 6 | intset |
| OBJ_ENCODING_SKIPLIST | 7 | skiplist |
| OBJ_ENCODING_EMBSTR | 8 | embstr |
| OBJ_ENCODING_QUICKLIST | 9 | quicklist |
| define OBJ_ENCODING_STREAM | 10 | — |
数据类型结构
String
Redis引入了一个SDS(Simple Dynamic String)类型,来表示String对象。
1 | struct sdshdr { |
自Redis3.2版本之后,为了更好的优化内存,把sdshdr分为sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdrhdr64。
1 | /* Note: sdshdr5 is never used, we just access the flags byte directly. |
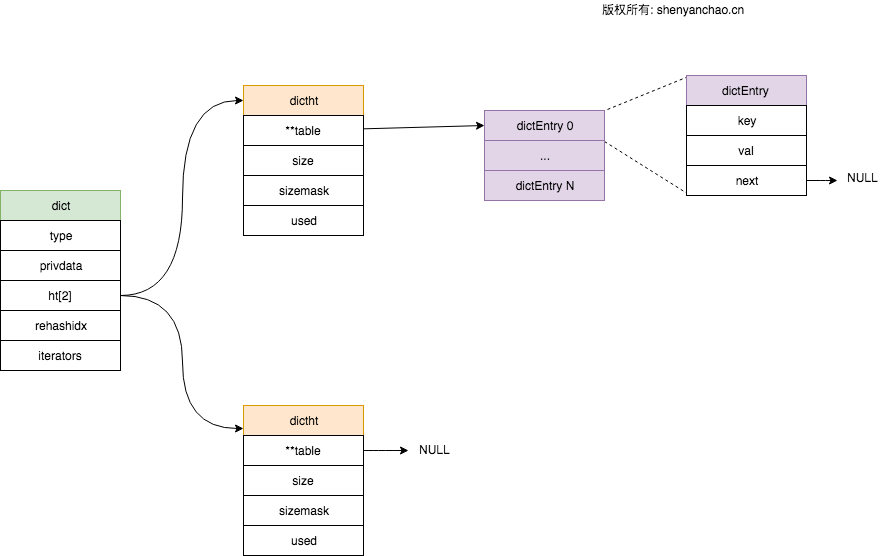
字典类型
dictEntry表示hash表的节点。
1 | /* |
dictht表示一个哈希表。
1 | /* |
dict代表了一个字典,需要注意的是dictht有2个,这个用来实现渐进式rehash。
1 | /* |
相关结构图示如下:
INTSET结构
用于保存INT类型集合的结构,很简单:
1 | typedef struct intset { |
内部维护了一个contents数组来保存具体的类型。
SKIPLIST(跳表)
1 | /* ZSETs use a specialized version of Skiplists */ |
图示表示为:
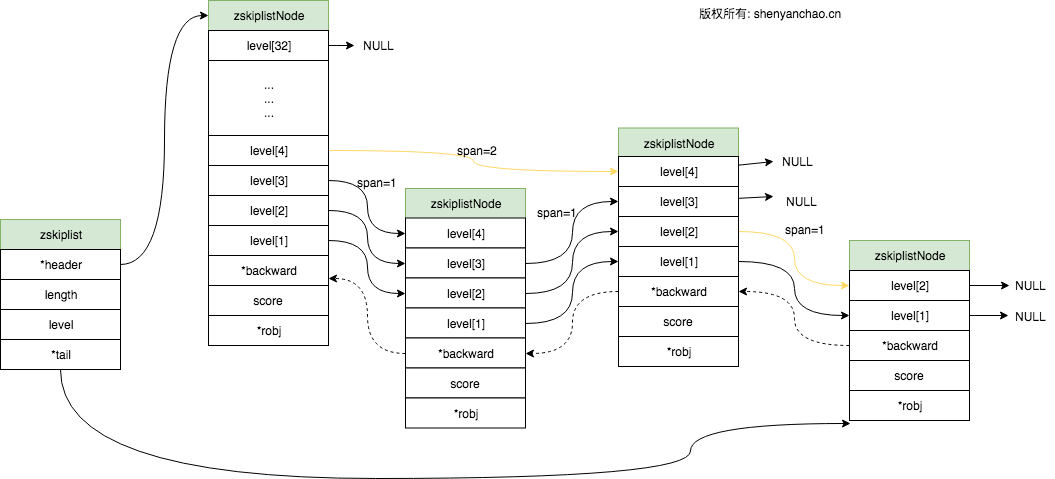
这个和常规意义上的跳表并没有区别。
LINKEDLIST
这是一个双向链表结构(adlist.h)。
1 | typedef struct listNode { |
具体的双向链表定义如下:
1 | /* |
链表操作的具体实现在adlist.c里实现,同正常的双向链表没有区别。
ZIPLIST
什么时候使用ZIPLIST编码呢?如何实现的呢?
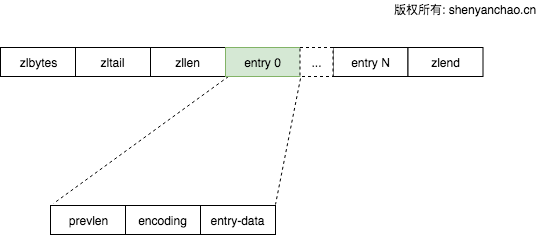
| 字段 | 含义 |
|---|---|
| zlbytes | 该字段是压缩链表的第一个字段,是无符号整型,占用4个字节。用于表示整个压缩链表占用的字节数(包括它自己)。 |
| zltail | 无符号整型,占用4个字节。用于存储从压缩链表头部到最后一个entry(不是尾元素zlend)的偏移量,在快速跳转到链表尾部的场景使用。 |
| zllen | 无符号整型,占用2个字节。用于存储压缩链表中包含的entry总数。 |
| zlend | 特殊的entry,用来表示压缩链表的末尾。占用一个字节,值为255(0xFF)。 |
Entry部分:
一般来说,一个entry由prevlen,encoding,entry-data三个字段组成,但当entry是个很小的整数时,会根据编码省略掉entry-data字段。
prevlen表示前一个entry的长度。
- 当长度小于255字节的时候,用一个字节存储。
- 当长度大于等于255字节的时候,用5个字节来存储。第1个字节设置为255(0xFF),后4个字节来存储前一个entry的长度。
encoding存储分为以下情况。
1.如果元素内容为字符串,encoding这样来表示。
| encoding值 | 可表示长度 | 存储 |
|---|---|---|
| 00xx xxxx | 6bit | — |
| 01xx xxxx xxxx xxxx | 14bit | 大端存储 |
| 1000 0000 xxxx xxxx xxxx xxxx xxxx xxxx xxxx xxxx | 32bit | 大端存储 |
2.如果元素为整数,encoding这样表示:
| encoding | 解释 |
|---|---|
| 1100 0000 | 表示数字占用后面2个字节 |
| 1101 0000 | 表示数字占用后面4个字节 |
| 1110 0000 | 表示数字占用后面8个字节 |
| 1111 0000 | 表示数字占用后面3个字节 |
| 1111 1110 | 表示数字占用后面1个字节 |
| 1111 1111 | 表示压缩链表中最后一个元素(特殊编码0xFF)。即zlend |
| 1111 xxxx | 表示只用后4位表示0 |
源码文档里举了这样的一个包含”2”和“5”的ZIPLIST来说明:
1 | 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
前4字节,表示为0x0f, 说明总共占用15字节。
接下来的4个字节,表示为0x0c,说明最后一个entry(这里是“5”)的offset是12.
接下来的2个字节表示zllen总共有0x02=2个entry。
接下来的2个字节00,前面一个长度为0(目前是第1个entry),接下来0xf3(11110011), 按上面的分析,这里3-1=2.
接下来的2个字节,02表示前一个entry长度为2, 0xf6(11110110)代表6-1=5。
最后一个字节0xff代表结束,最后一个。
接下来,如果在“5”后面插入“hello world”
1 | 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
注意到zlbytes变成了28, zltail变成了14, entries变成了3。新加入的entry“hello word”,02表示前一个长度为2. 0x0b(0000 1011)表示后面有数据有11个字节。紧跟其后的就是11个字节的“hello world”ASCII码。
QUICKLIST
QUICKLIST是一个ziplist的双向链表,这个定义很准确。它综合了LINKEDLIST和ZIPLIST.
1 | typedef struct quicklistNode { |
其中:
prev,next:分别指向前一个和后一个node,典型的双链表。
zl:指向ziplist结构,如果启用了压缩,那么指向的就是quicklistLZF结构了。
sz:表示指向ziplist的总大小。即使被压缩,也仍旧是未压缩的大小。
count:表示ziplist里面数据项的个数。
encoding:表示是否压缩(2表示LZF,1为RAW)。
container: 表示使用什么类型存数据。目前(NONE=1, ZIPLIST=2)
recompress: 表明这个数据是否压缩过。
attempted_compress: 测试用
extra: 扩展字段。
1 | /* quicklistLZF is a 4+N byte struct holding 'sz' followed by 'compressed'. |
sz: LZF压缩后的大小。
compressed: 存放压缩后ZIPLIST的char数组。
1 | /* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist. |
head,tail:分别指向头、尾
count: 所有ziplist数据项总和。
len: quicklistNode的总个数
fill: 16bit,ziplist大小设置。存放list-max-ziplist-size参数的值
compress: 16bit, 压缩深度设置。存放list-compress-depth参数的值。
简略图示如下:
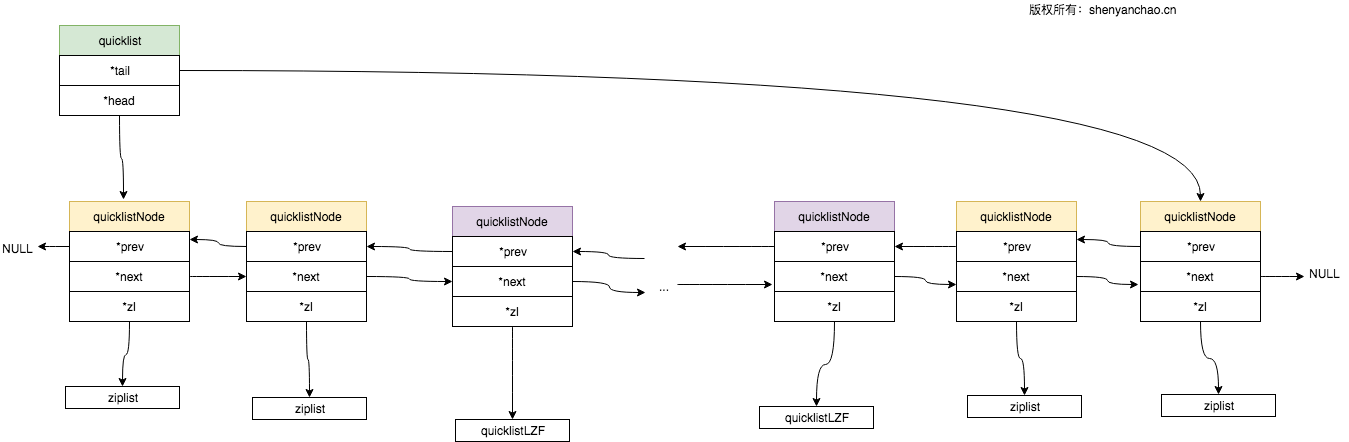
上图中redis.conf中配置如下:
1 | # 每个ziplist最大存多少个 |
quicklist总分利用了ziplist的压缩比高,规避了量大效率低的问题。redis 3.2之后,默认使用QUICKLIST来实现.
ZIPMAP
格式如下:
1 | <zmlen><len>"foo"<len><free>"bar"<len>"hello"<len><free>"world"0XFF |
zmlen: 1byte, 表示当前zipmap的长度。当长度>254的时候,这个不需要。总长度需要遍历拿到
len: 后面跟着值的长度。如果第1字节在0-253,代表是一个单字节产股。如果第1字节是254,表示后面有4字节表示具体长度。遇到255(0xFF)表示结尾。
free: 表示未用的字符串。这种情况存在于修改内容的时候,比如foo->hi,则有1个的空白。
数据编码一览
| 数据类型 | 一般情况编码 | 少量数据编码 | 数据为整形 |
|---|---|---|---|
| String | RAW | EMBSTR | INT |
| List | LINKEDLIST(3.2前)/QUICKLIST(3.2后) | ZIPLIST(3.2前) | — |
| Set | HT | — | INTSET |
| Hash | HT | ZIPMAP | — |
| ZSET | SKIPLIST | ZIPLIST | — |
String(OBJ_STRING)类型
EMBSTR(OBJ_ENCODING_EMBSTR)编码(长度小于<39/44使用这种类型):
1 | jemalloc chunk size = 64; |
所以:
Redis3.2前,64-16-8-1=39。
Redis3.2之后,64-16-3-1=44.
长度在39/44以内的话,可以直接存放在连续内存,省去了多次分配。
INT(OBJ_ENCODING_INT): 如果字符串都是整数的时候,使用INT编码。
ptr指针直接代表字符串的值。实际上Redis启动后,会默认创建10000个RedisObject, 用于代表地1-10000的整形,这个大小是可以配置的。
如果以上都不满足, 使用OBJ_ENCODING_RAW编码,即SDS类型。
List(OBJ_LIST)类型
在Redis3.2之后,统一使用OBJ_ENCODING_QUICKLIST来实现。
SET(OBJ_SET)类型
redis.conf配置文件里:
1 | set-max-intset-entries 512 |
意思是如果整数集合的元素个数超过512,则转为HT编码。当然,如果插入的是字符串,那也会直接转码,无视这个限制的。
HASH(OBJ_HASH)类型
redis.conf配置文件里:
1 | hash-max-ziplist-value 64 // ziplist中最大能存放的值长度 |
这些阈值,用于决定什么情况下使用何种类型编码。
以上可以看出。entry个数小于等于512并且value长度小于等于64的话才使用ZIPLIST,超出则选择HASHTABLE.
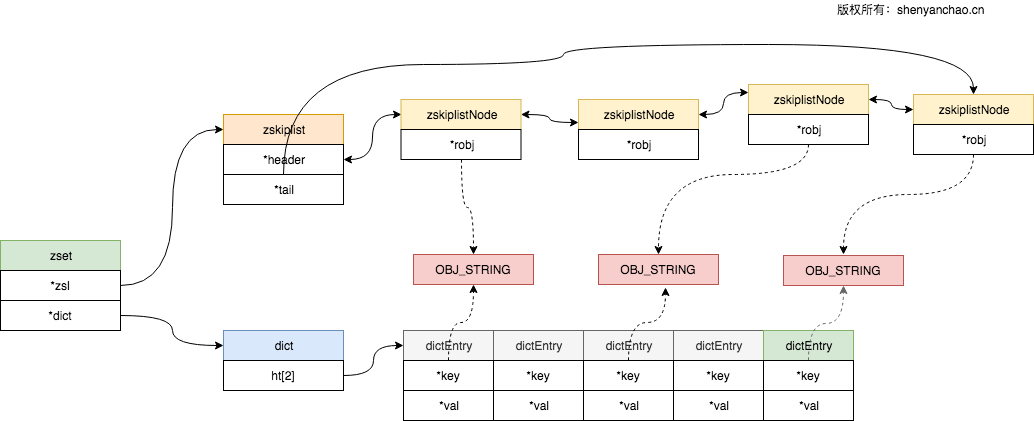
SortedSet(OBJ_ZSET)类型
有序集合定义为zset
1 | /* |
可以看出,里面由一个dict和一个zskiplist来实现。dict用来存储key-score对, zskiplist用于快速定位查找。
1 |
在entry个数<=128并且value长度<=64的时候,使用的是ziplist,否则使用SKIPLIST格式。
总结
Redis为了更大程度的提升性能,压缩数据大小, 在内存模型和数据结构上做了很多努力。